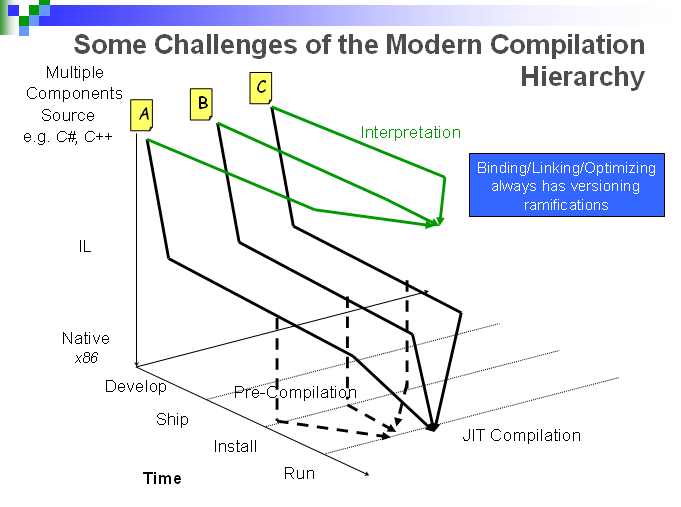
Nous ne pouvons pas, malgré les sommes faramineuses mobilisées, plusieurs centaines de millions d'euros pour des banques en internes, plusieurs milliards d'euros chez des fournisseurs specialisés de logiciels, aboutir à un systeme de gestion integré.
La richesse fonctionnelle à couvrir est enorme. Pour gerer la vie d'un produit que vous achetez dans un reseau bancaire par exemple: "vous beneficiez de 25% de la performance du cac40, plus un rendement garanti de 5% par an"
Il aura d'abord fallu .une demarche commerciale pour ce produit (gestion commerciale avant vente) .donner un prix (manipulation de données historiques, et de modeles), avec eventuellement des allers retours. Une fois les caracteristiques determinées .verrouiller les parametres du prix (hedger) .l'emeteur devra en interne emettre un ensemble de titres representant chacun une composante du produit. ce split est necessaire pour obtenir pour chaque produit les meilleures conditions de prix, ou satisfaire à des obligations juridiques. .Ce produit genere pour l'emetteur des expositions en change, en taux, en volatilité, et d'autres parametres .Pour couvrir ces parametres, il faut placer des ordres à des heures precises, correspondant au produit vendu .Les evolutions des parametres financiers genere des gains ou des pertes au niveau de l'emetteur, qui doit rapporter celles ci au niveau de sa hierarchie, à intervalles reguliers, puis au niveau comptable au comissaire aux comptes. .Les cellules de controle de risque internes monitorent aussi en permanence les evolutions des engagements pris, et surtout potentiels....
Etc, etc...
Pourquoi cet exemple est interessant? Parce que derriere ces problemes, il existe des enjeux financiers importants. Par ailleurs, ces enjeux existent de maniere concentrés chez plusieurs acteurs qui ont des moyens importants à mettre en face. Les conditions sont donc ideales.
Or il y a echec.
Le mur de la modelisation est atteint.
A fortiori, d'autres domaines qui sont confrontés à une complexité fonctionnelle aussi riche, mais dont les interets à mettre en place une solution sont dispersés, ou qui n'ont tout simplement pas ces moyens n'ont aucune chance de voir une solution informatique gerer leur domaine fonctionnel.
Revenons aux organisations qui ont donc le plus d'atouts de leur coté dans le cadre actuel : D'une part le mur de la modelisation est atteint. D'autre part, cette meme modelisation est à l'heure actuelle requise pour lancer des projets, car il y a des couts d'agence. un service sous traite à un autre la realisation d'un logiciel, il faut donc valider la facture generée, et pour ce faire, avoir prevu au prealable, et donc modelisé...
Nous sommes confrontés à un deadlock organisationnel.
Il faut donc changer d'organisation. Ce ne sont pas les autorisation pour engager des depenses en externe au nom d'un groupe d'interet qui vont disparaitre. Il va donc falloir trouver des moyens plus souples de developper des solutions, de les mettre en oeuvre, de les scaler, etc..
Il n'y a pas d'autres options que celle ci si l'on souhaite aller au dela du cycle logiciel actuel qui reste excessivement faible en dehors des grands systemes comme windows, chez les "vrais" utilisateurs d'informatique.
C'est pour cela qu'à travers toute les technologies mises en place, je vois celle qui favorisent et structurent l'emergence de la modelisation comme celles qui sont importantes.
La realisation est bien plus facile. Individuellement, les differents elements mis en oeuvre dans le modele complexe presenté de gestion d'un produit financier sont presque triviaux. collectivement ils deviennent tres compliqués. Architecturer ceux-ci pour integrer les changements sans bureaucratie excessive est impossible.
ps: Concernant les tags, ceux ci sont utilisés depuis fort longtemps par Reuters, qui classe ses depeches ainsi, par langue, pays, theme, etc.. Un article sur une emission d'emprunt en pologne interesse aussi bien le marché du credit que celui des taux d'interets, que les banquiers conseils etc.. A contrario, une news sur le president polonais qui se rend en allemagne limite l'interet des recherche par mots clefs..
Le probleme est que si Reuters utilise tres bien ces tags, les categories, le meta modele, est defini... par reuters! C'est la que se situe l'innovation des tags version web : la possiblité de se rassembler dans des categories communes, mais aussi la possiblité de se disperser pour discuter avec d'autres experts de choses qui n'existent pas dans l'esprit d'autres contemporains.